“Goldilocks” Agents and the Power of Custom Cognitive Architectures
The quickening evolution of more capable and reliable AI agents.
After ChatGPT, the next big turning point for AI was the arrival of agents that could use LLMs to interact with the world autonomously. Projects like AutoGPT skyrocketed in popularity, but then died down just as quickly as reality didn’t live up to the hype.
But this year something interesting started to happen—more realistic agents have come online and are gaining product traction, whether in customer support or coding. New ways to build and deploy agents are improving their performance and reliability.
This is important because agents are still key to the promise of AI: LLMs are great, but having the AI actually be able to plan and act on your behalf…that’s where things get really interesting. The more AI can be a worker rather than a tool, the more leverage it can provide us.
To explore this theme, we talked to Harrison Chase, founder and CEO of LangChain, on our Training Data podcast. Harrison started creating the infrastructure for LLM-powered agents before ChatGPT was even launched, and LangChain has become the default framework for developing agentic applications. He’s well positioned to help us learn about the evolution underway with agents.
The spectrum of agents
Let’s define an agent as any application that lets an LLM control the flow of the application.
With the benefit of 20/20 hindsight, it is clear that AutoGPT was too general and unconstrained to match our expectations. While it was exciting for capturing imagination, as a proof-of-concept for how LLMs might evolve to become general agents, it was too unconstrained to do useful things reliably.
The secret sauce behind the newest cohort of agents is that they use custom cognitive architectures to provide guardrails and a framework for controlling state to keep agents focused and not flying off the rails, while also embracing the full power and capabilities of LLMs.
One helpful way to frame the types of agents we see in the wild is a spectrum between simple, hard-coded agents and full-blown autonomous agents. This framing illuminates the “happy middle” where we are most likely to see useful agents emerge in the near to medium term.
On the simplest end of the spectrum, LLMs act as “routers” to decide which path to go down, with perhaps a classification step. In this case LLM calls govern the flow of the application, but most of the logic is still hard coded. At the other extreme, you have fully autonomous agents, like AutoGPT. Agents based on simple chains are not flexible or powerful enough to really take advantage of the LLM paradigm, while fully autonomous agents fail too often to be useful.
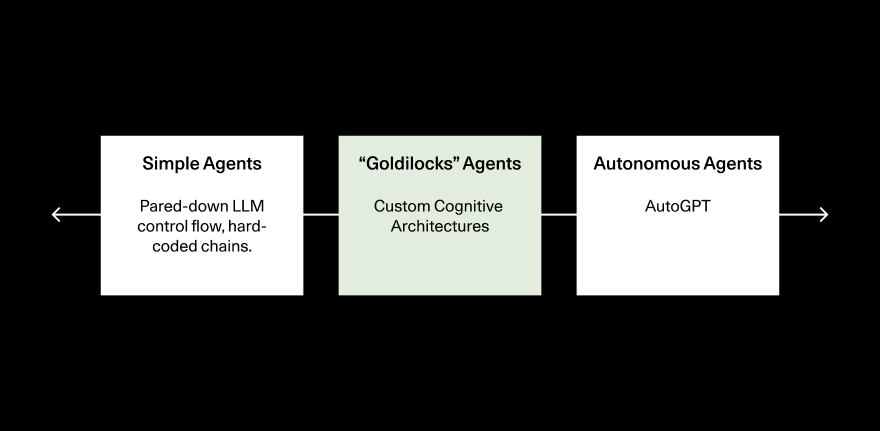
Developers are finding their Goldilocks “just right” balance in the middle of the agent spectrum, where they hand over a lot of the control flow to LLMs, but still maintain a set of rails and a sense of “state.”
The Goldilocks middle provides the best balance of power, flexibility and control, but it is also the hardest type of agent for developers to build—it requires a custom cognitive architecture that is structured but also non-deterministic. A fully autonomous agent can be implemented with very little code; at the extreme, you just have the agent in a for-loop picking an action every move. Simple agents are also easy to code, since there is very little stochastic variability to control for. Developing in the middle requires you to hand substantial control (and thus, stochastic variability) over to LLMs, while also controlling a high-level application flow and state management.
Harrison shared a brilliant quote from Jeff Bezos on our podcast, “Focus on what makes your beer taste better,” making an analogy between how breweries at the turn of the 20th century made their own electricity and tech companies ran their own infrastructure before AWS. In a world where agents fall over more often than not, where 12-13% on SWE-bench is considered state-of-the-art, implementing a custom cognitive architecture absolutely makes your beer taste better.
Keeping ahead of the models
But for how long? Harrison also raised this issue in his talk at our AI Ascent conference where he asked whether improvements in the underlying LLMs will subsume more and more of the reasoning and planning developers are building in the “happy middle.” In other words, are custom cognitive architectures a stop-gap solution?
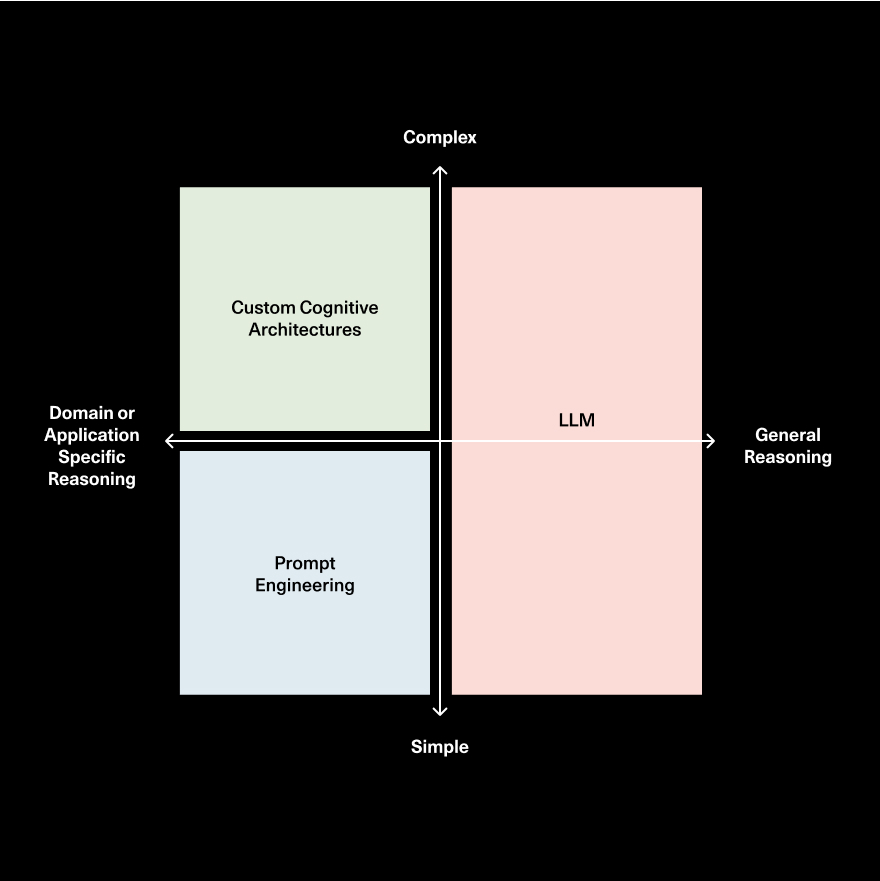
This is a fair question: many of the earliest prompt-engineering-based agent architectures (like chain of thought) became baked into future iterations of LLMs by default, obviating the need to build them around the LLM. We believe that many of the large research labs have their researchers focused squarely on the reasoning, planning and search problems.
Harrison’s take is that more and more general-purpose reasoning will become baked into the LLMs by default, but there is still a need for application or domain-specific reasoning. The way you plan and prosecute actions to reach your goals as a software engineer is vastly different from how you would work as a scientist, and moreover it’s different as a scientist at different companies. There is so much room for domain and application-specific reasoning that simply cannot efficiently be encoded in a general model.
Software 2.0
Developing applications with LLMs is a different paradigm from software 1.0 development and requires new approaches to observability and evaluation. Harrison’s bet is that many of the traditional software development tools are insufficient to deal with the non-deterministic nature of LLM applications. With agents and new ways of controlling application logic, monitoring the behavior of the application with observability and testing become paramount. If you are building a custom cognitive architecture, here are some things to think about:
- On application development: You probably need to design in a “state” graph which then needs to be managed and deployed with a persistence layer, background asynchronous orchestration, cyclical handling of state, etc. Harrison is seeing this pattern come up frequently in agent deployments, and LangGraph is intended to help developers build for this new paradigm.
- On observability and testing: Existing monitoring tools don’t provide the level of insights you need to trace what went wrong with an LLM call. And testing is different in a stochastic world, too—you’re not running a simple “test that 2=2” unit test that a computer can easily verify. Testing becomes a more nuanced concept with techniques like pairwise comparisons (e.g. Langsmith, Lmsys) and tracking improvements/regressions. All of this calls for a new set of developer tools.
What’s exciting about the rise of “Goldilocks” agents is the tremendous potential to create software that works on our behalf and that is within our control. Realizing this potential is not only dependent on the models getting better (they surely will) but also on this whole new ecosystem of tools to manage this radically new kind of application development.
This theme of crafting more reliable agents with custom cognitive architectures factors into our next episode, with Matan Grinberg and Eno Reyes of Factory, and in an upcoming episode with Clay Bevor of Sierra.

